Shirish Agarwal: Shantaram, The Pyramid, Japan s Hikikomori & Backpack

Shantaram
I know I have been quite behind in review of books but then that s life. First up is actually not as much as a shocker but somewhat of a pleasant surprise. So, a bit of background before I share the news. If you have been living under a rock, then about 10-12 years ago a book called Shantaram was released. While the book is said to have been released in 2003/4 I got it in my hand around 2008/09 or somewhere around that. The book is like a good meal, a buffet. To share the synopsis, Lin a 20 something Australian guy gets involved with a girl, she encourages him to get into heroin, he becomes a heroin user. And drugs, especially hard drugs need constant replenishment, it is a chemical thing. So, to fund those cravings, he starts to steal, rising to rob a bank and while getting away shoots a cop who becomes dead. Now either he surrenders or is caught is unclear, but he is tortured in the jail. So one day, he escapes from prison, lands up at home of somebody who owes him a favor, gets some money, gets a fake passport and lands up in Mumbai/Bombay as it was then known. This is from where the actual story starts. And how a 6 foot something Australian guy relying on his street smartness and know how the transformation happens from Lin to Shantaram. Now what I have shared is perhaps just 5% of the synopsis, as shared the real story starts here.
Now the good news, last week 4 episodes of Shantaram were screened by Apple TV. Interestingly, I have seen quite a number people turning up to buy or get this book and also sharing it on Goodreads. Now there seems to have been some differences from the book to TV. Now I m relying on 10-12 year back memory but IIRC Khaderbhai, one of the main characters who sort of takes Lin/Shantaram under his wing is an Indian. In the series, he is a western or at least looks western/Middle Eastern to me. Also, they have tried to reproduce 1980s in Mumbai/Bombay but dunno how accurate they were  My impression of that city from couple of visits at that point in time where they were still more tongas (horse-ridden carriages), an occasional two wheelers and not many three wheelers. Although, it was one of the more turbulent times as lot of agitation for worker rights were happening around that time and a lot of industrial action. Later that led to lot of closure of manufacturing in Bombay and it became more commercial. It would be interesting to know whether they shot it in actual India or just made a set somewhere in Australia, where it possibly might have been shot. The chawl of the book needs a bit of arid land and Australia has lots of it.
It is also interesting as this was a project that had who s who interested in it for a long time but somehow none of them was able to bring the project to fruition, the project seems to largely have an Australian cast as well as second generations of Indians growing in Australia. To take names, Amitabh Bacchan, Johnny Depp, Russel Crowe each of them wanted to make it into a feature film. In retrospect, it is good it was not into a movie, otherwise they would have to cut a lot of material and that perhaps wouldn t have been sufficient. Making it into a web series made sure they could have it in multiple seasons if people like it. There is a lot between now and 12 episodes to even guess till where it would leave you then. So, if you have not read the book and have some holidays coming up, can recommend it. The writing IIRC is easy and just flows. There is a bit of action but much more nuance in the book while in the web series they are naturally more about action. There is also quite a bit of philosophy between him and Kaderbhai and while the series touches upon it, it doesn t do justice but then again it is being commercially made.
Read the book, see the series and share your thoughts on what you think. It is possible that the series might go up or down but am sharing from where I see it, may do another at the end of the season, depending on where they leave it and my impressions.
Update A slight update from the last blog post. Seems Rishi Sunak seems would be made PM of UK. With Hunt as chancellor and Rishi Sunak, Austerity 2.0 seems complete. There have been numerous articles which share how austerity gives rises to fascism and vice-versa. History gives lot of lessons about the same. In Germany, when the economy was not good, it was all blamed on the Jews for number of years. This was the reason for rise of Hitler, and while it did go up by a bit, propaganda by him and his loyalists did the rest. And we know and have read about the Holocaust. Today quite a few Germans deny it or deny parts of it but that s how misinformation spreads. Also Hitler is looked now more as an aberration rather than something to do with the German soul. I am not gonna talk more as there is still lots to share and that actually perhaps requires its own blog post to do justice for the same.
My impression of that city from couple of visits at that point in time where they were still more tongas (horse-ridden carriages), an occasional two wheelers and not many three wheelers. Although, it was one of the more turbulent times as lot of agitation for worker rights were happening around that time and a lot of industrial action. Later that led to lot of closure of manufacturing in Bombay and it became more commercial. It would be interesting to know whether they shot it in actual India or just made a set somewhere in Australia, where it possibly might have been shot. The chawl of the book needs a bit of arid land and Australia has lots of it.
It is also interesting as this was a project that had who s who interested in it for a long time but somehow none of them was able to bring the project to fruition, the project seems to largely have an Australian cast as well as second generations of Indians growing in Australia. To take names, Amitabh Bacchan, Johnny Depp, Russel Crowe each of them wanted to make it into a feature film. In retrospect, it is good it was not into a movie, otherwise they would have to cut a lot of material and that perhaps wouldn t have been sufficient. Making it into a web series made sure they could have it in multiple seasons if people like it. There is a lot between now and 12 episodes to even guess till where it would leave you then. So, if you have not read the book and have some holidays coming up, can recommend it. The writing IIRC is easy and just flows. There is a bit of action but much more nuance in the book while in the web series they are naturally more about action. There is also quite a bit of philosophy between him and Kaderbhai and while the series touches upon it, it doesn t do justice but then again it is being commercially made.
Read the book, see the series and share your thoughts on what you think. It is possible that the series might go up or down but am sharing from where I see it, may do another at the end of the season, depending on where they leave it and my impressions.
Update A slight update from the last blog post. Seems Rishi Sunak seems would be made PM of UK. With Hunt as chancellor and Rishi Sunak, Austerity 2.0 seems complete. There have been numerous articles which share how austerity gives rises to fascism and vice-versa. History gives lot of lessons about the same. In Germany, when the economy was not good, it was all blamed on the Jews for number of years. This was the reason for rise of Hitler, and while it did go up by a bit, propaganda by him and his loyalists did the rest. And we know and have read about the Holocaust. Today quite a few Germans deny it or deny parts of it but that s how misinformation spreads. Also Hitler is looked now more as an aberration rather than something to do with the German soul. I am not gonna talk more as there is still lots to share and that actually perhaps requires its own blog post to do justice for the same.
The Pyramid by Henning Mankell
I had actually wanted to review this book but then the bomb called Shantaram appeared and I had to post it above. I had read two-three books before it, but most of them were about multiple beheadings and serial killers. Enough to put anybody into depression. I do not know if modern crime needs to show crime and desperation of and to such a level. Why I and most loved and continue to love Sherlock Holmes as most stories were not about gross violence but rather a homage to the art of deduction, which pretty much seems to be missing in modern crime thrillers rather than grotesque stuff.
In that, like a sort of fresh air I read/am reading the Pyramid by Henning Mankell. The book is about a character made by Monsieur Henning Mankell named Kurt Wallender. I am aware of the series called Wallender but haven t yet seen it. The book starts with Wallender as a beat cop around age 20 and on his first case. He is ambitious, wants to become a detective and has a narrow escape with death. I wouldn t go much into it as it basically gives you an idea of the character and how he thinks and what he does. He is more intuitive by nature and somewhat of a loner. Probably most detectives IRL are, dunno, have no clue. At least in the literary world it makes sense, in real world think there would be much irony for sure. This is speculation on my part, who knows.
Back to the book though. The book has 5 stories a sort of prequel one could say but also not entirely true. The first case starts when he is a beat cop in 1969 and he is just a beat cop. It is a kind of a prequel and a kind of an anthology as he covers from the first case to the 1990s where he is ending his career sort of.
Before I start sharing about the stories in the book, I found the foreword also quite interesting. It asks questions about the interplay of the role of welfare state and the Swedish democracy. Incidentally did watch couple of videos about a sort of mixed sort of political representation that happens in Sweden. It uses what is known as proportional representation. Ironically, Sweden made a turn to the far right this election season. The book was originally in Swedish and were translated to English by Ebba Segerberg and Laurie Thompson.
While all the stories are interesting, would share the last three or at least ask the questions of intrigue. Of course, to answer them you would need to read the book  So the last three stories I found the most intriguing.
The first one is titled Man on the Beach. Apparently, a gentleman goes to one of the beaches, a sort of lonely beach, hails a taxi and while returning suddenly dies. The Taxi driver showing good presence of mind takes it to hospital where the gentleman is declared dead on arrival. Unlike in India, he doesn t run away but goes to the cafeteria and waits there for the cops to arrive and take his statement. Now the man is in his early 40s and looks to be fit. Upon searching his pockets he is found to relatively well-off and later it turns out he owns a couple of shops. So then here are the questions ?
What was the man doing on a beach, in summer that beach is somewhat popular but other times not so much, so what was he doing there?
How did he die, was it a simple heart attack or something more? If he had been drugged or something then when and how?
These and more questions can be answered by reading the story Man on the Beach .
2. The death of a photographer Apparently, Kurt lives in a small town where almost all the residents have been served one way or the other by the town photographer. The man was polite and had worked for something like 40 odd years before he is killed/murdered. Apparently, he is murdered late at night. So here come the questions
a. The shop doesn t even stock any cameras and his cash box has cash. Further investigation reveals it is approximate to his average takeout for the day. So if it s not for cash, then what is the motive ?
b. The body was discovered by his cleaning staff who has worked for almost 20 years, 3 days a week. She has her own set of keys to come and clean the office? Did she give the keys to someone, if yes why?
c. Even after investigation, there is no scandal about the man, no other woman or any vices like gambling etc. that could rack up loans. Also, nobody seems to know him and yet take him for granted till he dies. The whole thing appears to be quite strange. Again, the answers lie in the book.
3. The Pyramid Kurt is sleeping one night when the telephone rings. The scene starts with a Piper Cherokee, a single piston aircraft flying low and dropping something somewhere or getting somebody from/on the coast of Sweden. It turns and after a while crashes. Kurt is called to investigate it. Turns out, the plane was supposed to be destroyed. On crash, both the pilot and the passenger are into pieces so only dental records can prove who they are. Same day or a day or two later, two seemingly ordinary somewhat elderly women, spinsters, by all accounts, live above the shop where they sell buttons and all kinds of sewing needs of the town. They seem middle-class. Later the charred bodies of the two sisters are found :(. So here come the questions
a.Did the plane drop something or pick something somebody up ? The Cherokee is a small plane so any plane field or something it could have landed up or if a place was somehow marked then could be dropped or picked up without actually landing.
b. The firefighter suspects arson started at multiple places with the use of petrol? The question is why would somebody wanna do that? The sisters don t seem to be wealthy and practically everybody has bought stuff from them. They weren t popular but weren t also unpopular.
c. Are the two crimes connected or unconnected? If connected, then how?
d. Most important question, why the title Pyramid is given to the story. Why does the author share the name Pyramid. Does he mean the same or the original thing? He could have named it triangle. Again, answers to all the above can be found in the book.
One thing I also became very aware of during reading the book that it is difficult to understand people s behavior and what they do. And this is without even any criminality involved in. Let s say for e.g. I die in some mysterious circumstances, the possibility of the police finding my actions in last days would be limited and this is when I have hearing loss. And this probably is more to do with how our minds are wired. And most people I know are much more privacy conscious/aware than I am.
So the last three stories I found the most intriguing.
The first one is titled Man on the Beach. Apparently, a gentleman goes to one of the beaches, a sort of lonely beach, hails a taxi and while returning suddenly dies. The Taxi driver showing good presence of mind takes it to hospital where the gentleman is declared dead on arrival. Unlike in India, he doesn t run away but goes to the cafeteria and waits there for the cops to arrive and take his statement. Now the man is in his early 40s and looks to be fit. Upon searching his pockets he is found to relatively well-off and later it turns out he owns a couple of shops. So then here are the questions ?
What was the man doing on a beach, in summer that beach is somewhat popular but other times not so much, so what was he doing there?
How did he die, was it a simple heart attack or something more? If he had been drugged or something then when and how?
These and more questions can be answered by reading the story Man on the Beach .
2. The death of a photographer Apparently, Kurt lives in a small town where almost all the residents have been served one way or the other by the town photographer. The man was polite and had worked for something like 40 odd years before he is killed/murdered. Apparently, he is murdered late at night. So here come the questions
a. The shop doesn t even stock any cameras and his cash box has cash. Further investigation reveals it is approximate to his average takeout for the day. So if it s not for cash, then what is the motive ?
b. The body was discovered by his cleaning staff who has worked for almost 20 years, 3 days a week. She has her own set of keys to come and clean the office? Did she give the keys to someone, if yes why?
c. Even after investigation, there is no scandal about the man, no other woman or any vices like gambling etc. that could rack up loans. Also, nobody seems to know him and yet take him for granted till he dies. The whole thing appears to be quite strange. Again, the answers lie in the book.
3. The Pyramid Kurt is sleeping one night when the telephone rings. The scene starts with a Piper Cherokee, a single piston aircraft flying low and dropping something somewhere or getting somebody from/on the coast of Sweden. It turns and after a while crashes. Kurt is called to investigate it. Turns out, the plane was supposed to be destroyed. On crash, both the pilot and the passenger are into pieces so only dental records can prove who they are. Same day or a day or two later, two seemingly ordinary somewhat elderly women, spinsters, by all accounts, live above the shop where they sell buttons and all kinds of sewing needs of the town. They seem middle-class. Later the charred bodies of the two sisters are found :(. So here come the questions
a.Did the plane drop something or pick something somebody up ? The Cherokee is a small plane so any plane field or something it could have landed up or if a place was somehow marked then could be dropped or picked up without actually landing.
b. The firefighter suspects arson started at multiple places with the use of petrol? The question is why would somebody wanna do that? The sisters don t seem to be wealthy and practically everybody has bought stuff from them. They weren t popular but weren t also unpopular.
c. Are the two crimes connected or unconnected? If connected, then how?
d. Most important question, why the title Pyramid is given to the story. Why does the author share the name Pyramid. Does he mean the same or the original thing? He could have named it triangle. Again, answers to all the above can be found in the book.
One thing I also became very aware of during reading the book that it is difficult to understand people s behavior and what they do. And this is without even any criminality involved in. Let s say for e.g. I die in some mysterious circumstances, the possibility of the police finding my actions in last days would be limited and this is when I have hearing loss. And this probably is more to do with how our minds are wired. And most people I know are much more privacy conscious/aware than I am.
Japan s Hikikomori
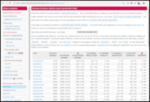
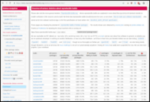
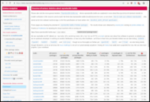
Japan has been a curious country. It was more or less a colonizer and somewhat of a feared power till it dragged the U.S. unnecessarily in World War 2. The result of the two atom bombs and the restitution meant that Japan had to build again from the ground up. It is also in a seismically unstable place as they have frequent earthquakes although the buildings are hardened/balanced to make sure that vibrations don t tear buildings apart. Had seen years ago on Natgeo a documentary that explains all that. Apart from that, Japan was helped by the Americans and there was good kinship between them till the 1980s till it signed the Plaza Accord which enhanced asset price bubbles that eventually burst. Something from which they are smarting even today. Japan has a constitutional monarchy. A somewhat history lesson or why it exists even today can be found here. Asset price bubbles of the 1980s, more than 50 percent of the population on zero hour contracts and the rest tend to suffer from overwork. There is a term called Karoshi that explains all. An Indian pig-pen would be two, two and a half times larger than a typical Japanese home. Most Japanese live in micro-apartments called konbachiku . All of the above stresses meant that lately many young Japanese people have become Hikikomori. Bloomberg featured about the same a couple of years back. I came to know about it as many Indians are given the idea of Japan being a successful country without knowing the ills and issues it faces. Even in that most women get the wrong end of the short stick i.e. even it they manage to find jobs, it would be most back-breaking menial work. The employment statistics of Japan s internal ministry tells its own story.

If you look at the data above, it seems that the between 2002 and 2019, the share of zero hour contracts has increased while regular work has decreased. This also means that those on the bottom of the ladder can no longer afford a home. There is and was a viral video called Lost in Manboo that went viral few years ago. It is a perfect set of storms. Add to that the Fukushima nuclear incident about which I had shared a few years ago. While the workers are blamed but all design decisions are taken by the management. And as was shown in numerous movies, documentaries etc. Interestingly, and somewhat ironically, the line workers knew the correct things to do and correct decisions to take unlike the management. The shut-ins story is almost a decade or two decades old. It is similar story in South Korea but not as depressive as the in Japan. It is somewhat depressive story but needed to be shared. The stories shared in the bloomberg article makes your heart ache
Backpacks
In and around 2015, I had bought a Targus backpack, very much similar to the Targus TSB194US-70 Motor 16-inch Backpack. That bag has given me a lot of comfort over the years but now has become frayed the zip sometimes work and sometimes doesn t. Unlike those days there are a bunch of companies now operating in India. There are eight different companies that I came to know about, Aircase, Harrisons Sirius, HP Oddyssey, Mokobara, Artic Hunter, Dell Pro Hybrid, Dell Roller Backpack and lastly the Decathlon Quechua Hiking backpack 32L NH Escape 500 . Now of all the above, two backpacks seem the best, the first one is Harrisons Sirius, with 45L capacity, I don t think I would need another bag at all. The runner-up is the Decathlon Quecha Hiking Backpack 32L. One of the better things in all the bags is that all have hidden pockets for easy taking in and out of passport while having being ant-theft. I do not have to stress how stressful it is to take out the passport and put it back in. Almost all the vendors have made sure that it is not a stress point anymore. The good thing about the Quecha is that they are giving 10 years warranty, the point to be asked is if that is does the warranty cover the zip. Zips are the first thing that goes out in bags.That actually has what happened to my current bag. Decathlon has a store in Wakad, Pune while I have reached out to the gentleman in charge of Harrisons India to see if they have a reseller in Pune. So hopefully, in next one week I should have a backpack that isn t spilling with things all over the place, whichever I m able to figure out.
So the last three stories I found the most intriguing.
The first one is titled Man on the Beach. Apparently, a gentleman goes to one of the beaches, a sort of lonely beach, hails a taxi and while returning suddenly dies. The Taxi driver showing good presence of mind takes it to hospital where the gentleman is declared dead on arrival. Unlike in India, he doesn t run away but goes to the cafeteria and waits there for the cops to arrive and take his statement. Now the man is in his early 40s and looks to be fit. Upon searching his pockets he is found to relatively well-off and later it turns out he owns a couple of shops. So then here are the questions ?
What was the man doing on a beach, in summer that beach is somewhat popular but other times not so much, so what was he doing there?
How did he die, was it a simple heart attack or something more? If he had been drugged or something then when and how?
These and more questions can be answered by reading the story Man on the Beach .
2. The death of a photographer Apparently, Kurt lives in a small town where almost all the residents have been served one way or the other by the town photographer. The man was polite and had worked for something like 40 odd years before he is killed/murdered. Apparently, he is murdered late at night. So here come the questions
a. The shop doesn t even stock any cameras and his cash box has cash. Further investigation reveals it is approximate to his average takeout for the day. So if it s not for cash, then what is the motive ?
b. The body was discovered by his cleaning staff who has worked for almost 20 years, 3 days a week. She has her own set of keys to come and clean the office? Did she give the keys to someone, if yes why?
c. Even after investigation, there is no scandal about the man, no other woman or any vices like gambling etc. that could rack up loans. Also, nobody seems to know him and yet take him for granted till he dies. The whole thing appears to be quite strange. Again, the answers lie in the book.
3. The Pyramid Kurt is sleeping one night when the telephone rings. The scene starts with a Piper Cherokee, a single piston aircraft flying low and dropping something somewhere or getting somebody from/on the coast of Sweden. It turns and after a while crashes. Kurt is called to investigate it. Turns out, the plane was supposed to be destroyed. On crash, both the pilot and the passenger are into pieces so only dental records can prove who they are. Same day or a day or two later, two seemingly ordinary somewhat elderly women, spinsters, by all accounts, live above the shop where they sell buttons and all kinds of sewing needs of the town. They seem middle-class. Later the charred bodies of the two sisters are found :(. So here come the questions
a.Did the plane drop something or pick something somebody up ? The Cherokee is a small plane so any plane field or something it could have landed up or if a place was somehow marked then could be dropped or picked up without actually landing.
b. The firefighter suspects arson started at multiple places with the use of petrol? The question is why would somebody wanna do that? The sisters don t seem to be wealthy and practically everybody has bought stuff from them. They weren t popular but weren t also unpopular.
c. Are the two crimes connected or unconnected? If connected, then how?
d. Most important question, why the title Pyramid is given to the story. Why does the author share the name Pyramid. Does he mean the same or the original thing? He could have named it triangle. Again, answers to all the above can be found in the book.
One thing I also became very aware of during reading the book that it is difficult to understand people s behavior and what they do. And this is without even any criminality involved in. Let s say for e.g. I die in some mysterious circumstances, the possibility of the police finding my actions in last days would be limited and this is when I have hearing loss. And this probably is more to do with how our minds are wired. And most people I know are much more privacy conscious/aware than I am.
Japan s Hikikomori
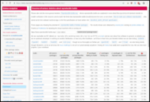
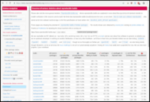
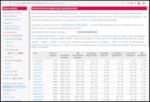
Japan has been a curious country. It was more or less a colonizer and somewhat of a feared power till it dragged the U.S. unnecessarily in World War 2. The result of the two atom bombs and the restitution meant that Japan had to build again from the ground up. It is also in a seismically unstable place as they have frequent earthquakes although the buildings are hardened/balanced to make sure that vibrations don t tear buildings apart. Had seen years ago on Natgeo a documentary that explains all that. Apart from that, Japan was helped by the Americans and there was good kinship between them till the 1980s till it signed the Plaza Accord which enhanced asset price bubbles that eventually burst. Something from which they are smarting even today. Japan has a constitutional monarchy. A somewhat history lesson or why it exists even today can be found here. Asset price bubbles of the 1980s, more than 50 percent of the population on zero hour contracts and the rest tend to suffer from overwork. There is a term called Karoshi that explains all. An Indian pig-pen would be two, two and a half times larger than a typical Japanese home. Most Japanese live in micro-apartments called konbachiku . All of the above stresses meant that lately many young Japanese people have become Hikikomori. Bloomberg featured about the same a couple of years back. I came to know about it as many Indians are given the idea of Japan being a successful country without knowing the ills and issues it faces. Even in that most women get the wrong end of the short stick i.e. even it they manage to find jobs, it would be most back-breaking menial work. The employment statistics of Japan s internal ministry tells its own story.
If you look at the data above, it seems that the between 2002 and 2019, the share of zero hour contracts has increased while regular work has decreased. This also means that those on the bottom of the ladder can no longer afford a home. There is and was a viral video called Lost in Manboo that went viral few years ago. It is a perfect set of storms. Add to that the Fukushima nuclear incident about which I had shared a few years ago. While the workers are blamed but all design decisions are taken by the management. And as was shown in numerous movies, documentaries etc. Interestingly, and somewhat ironically, the line workers knew the correct things to do and correct decisions to take unlike the management. The shut-ins story is almost a decade or two decades old. It is similar story in South Korea but not as depressive as the in Japan. It is somewhat depressive story but needed to be shared. The stories shared in the bloomberg article makes your heart ache
Backpacks
In and around 2015, I had bought a Targus backpack, very much similar to the Targus TSB194US-70 Motor 16-inch Backpack. That bag has given me a lot of comfort over the years but now has become frayed the zip sometimes work and sometimes doesn t. Unlike those days there are a bunch of companies now operating in India. There are eight different companies that I came to know about, Aircase, Harrisons Sirius, HP Oddyssey, Mokobara, Artic Hunter, Dell Pro Hybrid, Dell Roller Backpack and lastly the Decathlon Quechua Hiking backpack 32L NH Escape 500 . Now of all the above, two backpacks seem the best, the first one is Harrisons Sirius, with 45L capacity, I don t think I would need another bag at all. The runner-up is the Decathlon Quecha Hiking Backpack 32L. One of the better things in all the bags is that all have hidden pockets for easy taking in and out of passport while having being ant-theft. I do not have to stress how stressful it is to take out the passport and put it back in. Almost all the vendors have made sure that it is not a stress point anymore. The good thing about the Quecha is that they are giving 10 years warranty, the point to be asked is if that is does the warranty cover the zip. Zips are the first thing that goes out in bags.That actually has what happened to my current bag. Decathlon has a store in Wakad, Pune while I have reached out to the gentleman in charge of Harrisons India to see if they have a reseller in Pune. So hopefully, in next one week I should have a backpack that isn t spilling with things all over the place, whichever I m able to figure out.
 Now that the root cause is clear, I guess RedHat will push out a fix for the
openssl 3.0.1 based release they have in RHEL/CentOS 9. Until that is available
at least stunnel and keepalived are known to be affected. If you run stunnel
on something public it's not that pretty, because already a low rate of TCP
connections will result in a DoS condition.
Now that the root cause is clear, I guess RedHat will push out a fix for the
openssl 3.0.1 based release they have in RHEL/CentOS 9. Until that is available
at least stunnel and keepalived are known to be affected. If you run stunnel
on something public it's not that pretty, because already a low rate of TCP
connections will result in a DoS condition.





 In June I travelled to see Nine Inch Nails perform two nights at the
In June I travelled to see Nine Inch Nails perform two nights at the 














 Our local Debian user group gathered on Sunday August 28th
Our local Debian user group gathered on Sunday August 28th Once we had serial access, wiping the flash and re-installing OpenWRT fixed our
problem. A quick
Once we had serial access, wiping the flash and re-installing OpenWRT fixed our
problem. A quick 
 As always, thanks to the Debian project for granting us a budget to rent the
venue and to buy some food.
As always, thanks to the Debian project for granting us a budget to rent the
venue and to buy some food.
















 Last month I wrote about how
Last month I wrote about how  As a board, we have been working on several initiatives to make the Foundation a better asset for the GNOME Project. We re working on a number of threads in parallel, so I wanted to explain the big picture a bit more to try and connect together things like the new ED search and the bylaw changes.
We re all here to see free and open source software succeed and thrive, so that people can be be truly empowered with agency over their technology, rather than being passive consumers. We want to bring GNOME to as many people as possible so that they have computing devices that they can inspect, trust, share and learn from.
In previous years we ve tried to boost the relevance of GNOME (or technologies such as GTK) or solicit donations from businesses and individuals with existing engagement in FOSS ideology and technology. The problem with this approach is that we re mostly addressing people and organisations who are already supporting or contributing FOSS in some way. To truly scale our impact, we need to look to the outside world, build better awareness of GNOME outside of our current user base, and find opportunities to secure funding to invest back into the GNOME project.
The Foundation supports the GNOME project with infrastructure, arranging conferences, sponsoring hackfests and travel, design work, legal support, managing sponsorships, advisory board, being the fiscal sponsor of GNOME, GTK, Flathub and we will keep doing all of these things. What we re talking about here are additional ways for the Foundation to support the GNOME project we want to go beyond these activities, and invest into GNOME to grow its adoption amongst people who need it. This has a cost, and that means in parallel with these initiatives, we need to find partners to fund this work.
Neil has previously talked about themes such as education, advocacy, privacy, but we ve not previously translated these into clear specific initiatives that we would establish in addition to the Foundation s existing work. This is all a work in progress and we welcome any feedback from the community about refining these ideas, but here are the current strategic initiatives the board is working on. We ve been thinking about growing our community by encouraging and retaining diverse contributors, and addressing evolving computing needs which aren t currently well served on the desktop.
Initiative 1. Welcoming newcomers. The community is already spending a lot of time welcoming newcomers and teaching them the best practices. Those activities are as time consuming as they are important, but currently a handful of individuals are running initiatives such as GSoC, Outreachy and outreach to Universities. These activities help bring diverse individuals and perspectives into the community, and helps them develop skills and experience of collaborating to create Open Source projects. We want to make those efforts more sustainable by finding sponsors for these activities. With funding, we can hire people to dedicate their time to operating these programs, including paid mentors and creating materials to support newcomers in future, such as developer documentation, examples and tutorials. This is the initiative that needs to be refined the most before we can turn it into something real.
Initiative 2: Diverse and sustainable Linux app ecosystem. I spoke at the Linux App Summit about the work that GNOME and Endless has been supporting in Flathub, but this is an example of something which has a great overlap between commercial, technical and mission-based advantages. The key goal here is to improve the financial sustainability of participating in our community, which in turn has an impact on the diversity of who we can expect to afford to enter and remain in our community. We believe the existence of this is critically important for individual developers and contributors to unlock earning potential from our ecosystem, through donations or app sales. In turn, a healthy app ecosystem also improves the usefulness of the Linux desktop as a whole for potential users. We believe that we can build a case for commercial vendors in the space to join an advisory board alongside with GNOME, KDE, etc to input into the governance and contribute to the costs of growing Flathub.
Initiative 3: Local-first applications for the GNOME desktop. This is what Thib has been starting to discuss on Discourse,
As a board, we have been working on several initiatives to make the Foundation a better asset for the GNOME Project. We re working on a number of threads in parallel, so I wanted to explain the big picture a bit more to try and connect together things like the new ED search and the bylaw changes.
We re all here to see free and open source software succeed and thrive, so that people can be be truly empowered with agency over their technology, rather than being passive consumers. We want to bring GNOME to as many people as possible so that they have computing devices that they can inspect, trust, share and learn from.
In previous years we ve tried to boost the relevance of GNOME (or technologies such as GTK) or solicit donations from businesses and individuals with existing engagement in FOSS ideology and technology. The problem with this approach is that we re mostly addressing people and organisations who are already supporting or contributing FOSS in some way. To truly scale our impact, we need to look to the outside world, build better awareness of GNOME outside of our current user base, and find opportunities to secure funding to invest back into the GNOME project.
The Foundation supports the GNOME project with infrastructure, arranging conferences, sponsoring hackfests and travel, design work, legal support, managing sponsorships, advisory board, being the fiscal sponsor of GNOME, GTK, Flathub and we will keep doing all of these things. What we re talking about here are additional ways for the Foundation to support the GNOME project we want to go beyond these activities, and invest into GNOME to grow its adoption amongst people who need it. This has a cost, and that means in parallel with these initiatives, we need to find partners to fund this work.
Neil has previously talked about themes such as education, advocacy, privacy, but we ve not previously translated these into clear specific initiatives that we would establish in addition to the Foundation s existing work. This is all a work in progress and we welcome any feedback from the community about refining these ideas, but here are the current strategic initiatives the board is working on. We ve been thinking about growing our community by encouraging and retaining diverse contributors, and addressing evolving computing needs which aren t currently well served on the desktop.
Initiative 1. Welcoming newcomers. The community is already spending a lot of time welcoming newcomers and teaching them the best practices. Those activities are as time consuming as they are important, but currently a handful of individuals are running initiatives such as GSoC, Outreachy and outreach to Universities. These activities help bring diverse individuals and perspectives into the community, and helps them develop skills and experience of collaborating to create Open Source projects. We want to make those efforts more sustainable by finding sponsors for these activities. With funding, we can hire people to dedicate their time to operating these programs, including paid mentors and creating materials to support newcomers in future, such as developer documentation, examples and tutorials. This is the initiative that needs to be refined the most before we can turn it into something real.
Initiative 2: Diverse and sustainable Linux app ecosystem. I spoke at the Linux App Summit about the work that GNOME and Endless has been supporting in Flathub, but this is an example of something which has a great overlap between commercial, technical and mission-based advantages. The key goal here is to improve the financial sustainability of participating in our community, which in turn has an impact on the diversity of who we can expect to afford to enter and remain in our community. We believe the existence of this is critically important for individual developers and contributors to unlock earning potential from our ecosystem, through donations or app sales. In turn, a healthy app ecosystem also improves the usefulness of the Linux desktop as a whole for potential users. We believe that we can build a case for commercial vendors in the space to join an advisory board alongside with GNOME, KDE, etc to input into the governance and contribute to the costs of growing Flathub.
Initiative 3: Local-first applications for the GNOME desktop. This is what Thib has been starting to discuss on Discourse,